Building the Canonical Layer (What it actually looks like as a system)
Two weeks ago I wrote about why the output layer is commoditizing. Last week I described what a canonical layer is — the proprietary context inside your organization that AI can't access from public sources, and why it's the only competitive advantage left when everyone's running the same tools.

Fair warning: this will be more technical than the previous two posts. Not engineering-level technical, but specific enough that you'll leave with an actual architecture in your head, not just a framework to nod at.
The problem with how PMMs currently store knowledge
Before you can build a canonical layer, you need to be honest about where your knowledge lives right now. For most PMM teams, it's scattered across a handful of places: a message house doc that's three versions out of date, a Notion wiki that was curated once and then quietly abandoned, a Confluence page nobody can find, a Slack thread where someone summarized a win/loss debrief and it was brilliant for the 48 hours before it scrolled out of view. The knowledge exists. It just isn't structured in a way that's queryable.
That distinction matters more than it sounds. When you hand an AI a flat document — a positioning PDF, a message house in slide form, a competitive brief — it reads it the way a person skimming it would. It pulls out phrases it recognizes, synthesizes them with everything else it knows, and produces something directionally related to what you gave it.
That on its own is not grounding. That's just input. And input that isn't structured gets blended with everything else the model already knows, which is exactly the public corpus we've been talking about for two weeks. Your message house doc doesn't override the model's priors. It competes with them.
A canonical layer is different. It's not a document repository, but instead is a structured graph of approved claims — organized into domains, versioned, locked to specific owners, and queryable by type.
The difference between "we have a message house" and "we have a message house domain" is the difference between context and architecture.
What the architecture actually looks like
The canonical layer has three components. They build on each other.
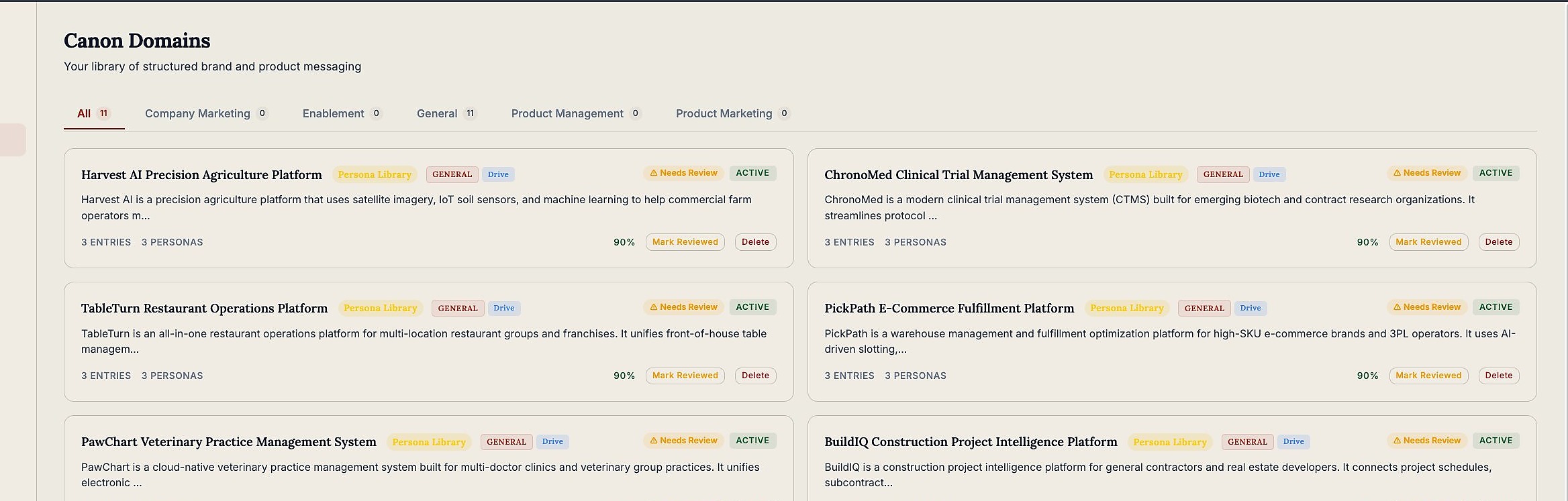
1. Canon Domains
A domain is the top-level namespace for a category of knowledge. For PMM, the obvious one is a Message House — but you'd also want domains for competitive positioning, persona libraries, objection handlers, and product proof points.
Each domain has an owner. Not a team. A specific person with authority to approve, lock, and version entries inside that domain. This matters for governance reasons I'll come back to.
2. Canon Entries
Inside each domain, knowledge lives as atomic entries. Not paragraphs. Not sections. Singular, structured assertions.
A canon entry for a message house pillar looks something like this:

That's the unit...a single claim, with one owner, in one version. Locked against paraphrase.
When your AI generates a battlecard, it doesn't summarize your positioning doc and hope for the best. It traverses these entries directly, retrieves the locked claim, and cites it verbatim. The output is only as good as what's in the canon — but what's in the canon is controlled by a person with context and accountability, not a model making probabilistic guesses.
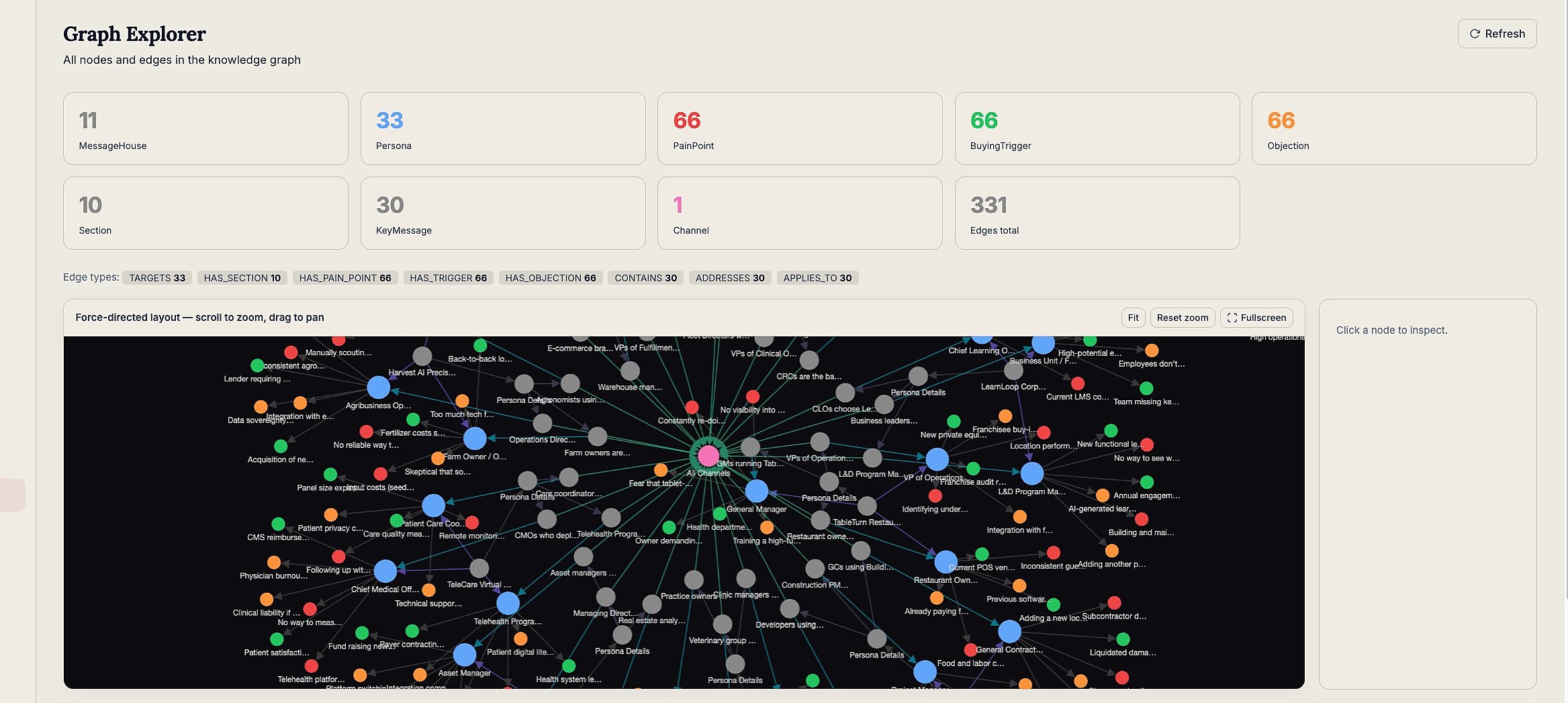
3. The Knowledge Graph
The entries don't just sit in a flat list. They're connected. A message house pillar connects to the personas it targets, which connect to their pain points, which connect to the objections they'll raise, which connect to the approved responses. Every relationship is an explicit edge in the graph.
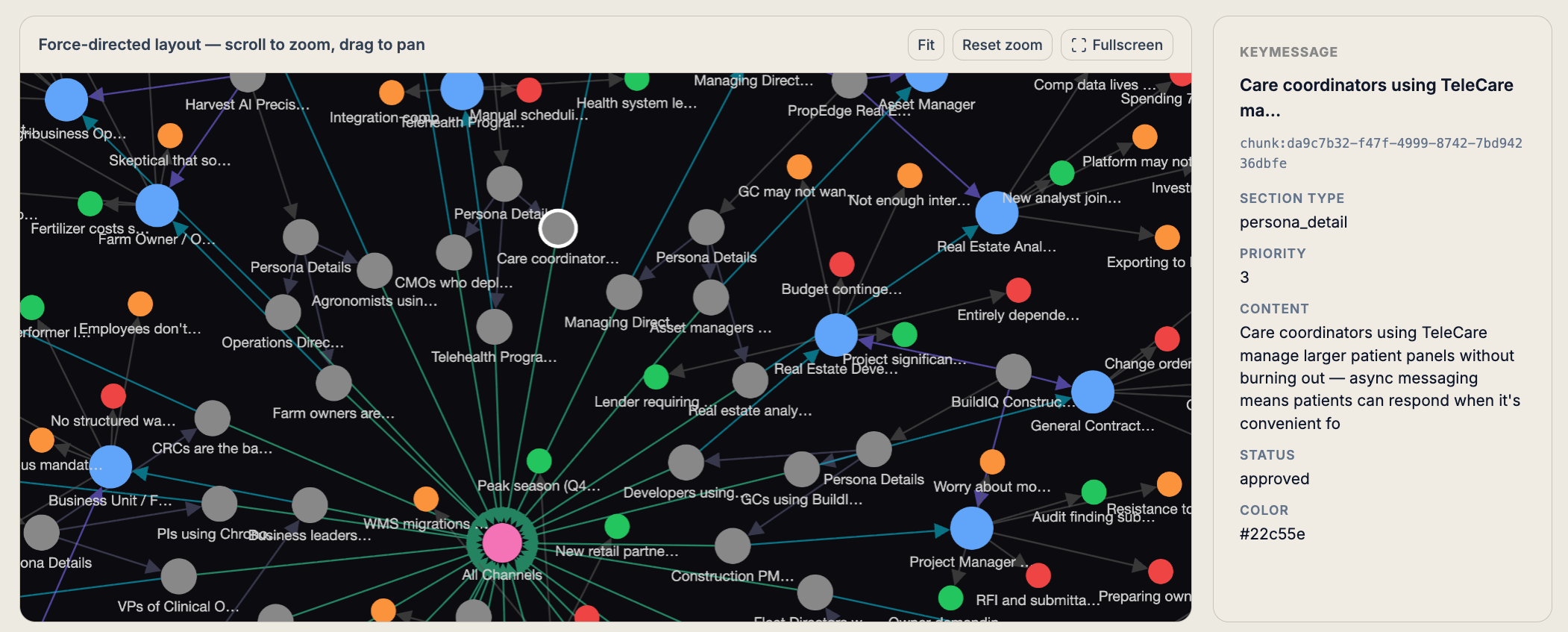
This is the part that most knowledge management systems skip. They index documents. They don't model relationships. The graph matters because it's what allows an AI to answer a question like "what objection does a VP of HR Operations raise when evaluating us against a legacy HRIS, and what's the approved response?" — by traversing a path through the graph, not by guessing from context.
How it connects to your AI tooling
Here's where the architecture pays off. The canonical layer connects to your AI tools via MCP — the Model Context Protocol, which is how AI systems expose external data sources as callable tools rather than static context. Once your canonical layer is registered as an MCP server, an AI assistant working on a deliverable can query it directly.
A session generating a competitive battlecard looks like this:

That last step is the one most teams skip. The alignment scorer catches claims the model generated that aren't grounded in the canon — statistics it inferred, product capabilities it embellished, category language it pulled from its training data. Before the battlecard ships, a human reviews the flags. What passes the audit is grounded. What doesn't gets corrected or removed.
The four-step loop — discover, retrieve, generate, audit — is what makes this different from generating content with a prompt and hoping it's accurate. The hope is gone. The contract is explicit.
The drift problem
Here's the governance angle most people don't think about when they start building this.
Your canonical layer isn't static. Products ship. Proof points change. Win/loss patterns shift. A claim that was accurate in Q1 may be wrong by Q3, but it's still sitting in your message house doc, still getting pulled into generated content, still being used by sales reps who have no idea it's outdated.
In a structured canonical layer, entries have explicit dependencies. A core value proposition entry in your message house connects to the proof points that support it, which connect to the customer references that validate them. When a proof point changes — a customer churns, a stat gets updated, a product capability ships — the system flags every downstream entry and artifact that depends on it.
That cascade is what a document repository can't do. A PDF doesn't know what depends on it. A canon entry does.
What it takes to actually build one
I'm not going to understate the work. Building a canonical layer takes time that looks unproductive by conventional PMM metrics. You're not making decks. You're not writing briefs. You're doing extraction work — pulling knowledge out of conversations, call recordings, Slack threads, win/loss interviews, and structuring it into atomic entries someone can audit.
The canonical layer I've been building and running in my own work took months to get to a point where it was genuinely useful. Not because the technology is hard to set up — it isn't — but because the hard part is knowledge capture, not infrastructure. Getting a product manager to sit with you for two hours and articulate why the architecture works a certain way and what that unlocks competitively. Getting sales to log the objections they're hearing in every deal, not just close them and move on. Getting customer success to surface what's coming up in renewals before it becomes a churn signal.
That work doesn't produce an artifact. It builds the input layer that makes every subsequent artifact better than what your competitor is generating with the same tools.
The channel mapping — knowing that a sales deck version of a pillar should be different from the LinkedIn version, not because the claim changes but because the context does — is another layer of structure most PMMs don't build intentionally.

This is what differentiation looks like now
Post 1 of this series was about the output layer commoditizing. Post 2 was about why proprietary context is the only thing left to differentiate on.
This is the answer to both. When everyone has access to the same generation tools, the competitive advantage isn't in how fast you can produce content. It's in what you feed those tools. A canonical layer built from real customer language, real win/loss patterns, real field feedback, and real product context will produce output that diverges from the category average — because the input diverged first.
The screenshots in this post are from MsgStack — an open-source project I built as a public proof of concept for this architecture. It's not a product of itself, but rather a demonstration that the canonical layer is buildable, not theoretical. The principles behind it are the same ones I've been applying in my own work — the internal version we've been building has grown to 73 message houses connected to AI assistants across sales, marketing, and field teams. Different implementation. Same idea.
MsgStack exists because I wanted other PMMs to have something concrete to look at — an actual system, not a framework slide. Fork it, adapt it, ignore it and build your own. The point isn't the tool. It's the architecture.
The canonical layer isn't a new category of software. It's a new responsibility for PMM. The teams that build it will produce content that's not just faster — it's differentiated in a way that volume alone can't replicate.
I'm speaking at the Product Marketing Alliance Seattle Summit on June 17th about what PMM is actually for when the output layer commoditizes. On June 18th I'm running a masterclass on building canonical layers in practice. If you're going to be there, come find me.
MsgStack is open source under Apache 2.0. msgstack.ai · GitHub
Discussion
Sign in to leave a comment
Uses your Google account — no password needed.